Стэнфорд со скрипом домучал экспериментальный онлайн ИИ-курс.
По какому-то недоразумению в название курса вкралось слово "интеллект". Никакого определения интеллекту дано не было (если не считать нелепого но симптоматичного определения "рационального поведения" как стремления к максимальной выгоде). Как делать человекоподобные интеллекты - никто так и не рассказал. Зато пробежались галопом по всяческим областям знаний:
- поиск по дереву
- теория вероятностей
- классификация
- логика
- планирование
- скрытые марковские модели
- теория игр
- распознавание изображений
- планирование движений робота
- обработка естественного языка
Ядро "искусственного интеллекта", с точки зрения стэнфордских гур (как я их понял), состоит из 3-х частей:
1. формулы Байеса
2. среднеквадратического отклонения
3. обученного естественного интеллекта...
"Специалисты" по искусственному интеллекту парадоксально, обучая якобы ИИ, призывают студентов использовать свой интеллект для решения задач, вместо того, чтобы изучать работу естественного интеллекта, создавать интеллект искусственный и перекладывать свои задачи на него. Это как если бы изобретатель "самодвижущейся повозки" вместо изобретения двигателя впрягался в повозку сам.
Но следует отдать должное, как минимум, Норвигу, он осознаёт нелепость данной ситуации и честно признаётся, что разделение на "разные" подходы и "разные" задачи - это исторически сложившийся трудноустранимый казус, цитирую (
видео с 4:20 по 7:10):
"Студент из Буэнос-Айреса спрашивает: существует ли связь между марковскими процессами принятия решений и теорией игр? Похоже, между ними есть что-то общее.
Питер Норвиг: замечательный вопрос. Он также возникал у нас на занятиях, тут, в Стэнфорде.
Мы рассматривали несколько подходов к планированию действий. Мы начали с поиска в пространстве состояний, который работает наилучшим образом в задачах с детерминированной средой и агентом без сенсоров. Затем мы перешли к классическому планированию, который работает с более абстрактными и сложными представлениями. Потом мы добавили агенту возможность чувствовать среду, что выходит за рамки классического планирования. Мы также говорили о марковских процессах принятия решений, чтобы решать задачи, в которых действия происходят стохастически, и о теории игр, чтобы решать задачи в условиях противодействия.
Каждое из этих направлений исторически развивалось раздельно и имеет собственную терминологию и собственные методы. Они охватывают разные виды сложностей среды. Но, когда вы применяете эти методы в реальных задачах, начиная, например, с классического планирования и добавляя к нему стохастичность, сенсоры и т.д., тогда они начинают сливаться, все методы начинают вести к одному и тому же.
Поэтому исторические различия кажутся непонятными. Номенклатура до сих пор остаётся разной, это сбивает с толку, и я прошу прощения за это. Но разные подходы имеют различное основное применение, они хороши в разных задачах. Если взять, к примеру, марковские процессы принятия решений, то они хорошо работают в задачах навигации робота в комнате, где робот может очень легко перемещатся из одного места в другое, и возвращаться в одно и то же место много раз. Так что вы можете сказать, что вместо пространства состояний проще рассматривать перемещения с места на место.
Сравним этот метод с поиском по игровым деревьям или теорией игр в такой игре как, скажем, Го. Мы кладём чёрный камень на один пункт и здесь у нас есть подобие некоторого дискретного состояния в котором у нас есть 1 чёрный камень на данном пункте. В Го возможно снять чёрный камень и заменить его на белый но это случается редко. Поэтому реально в Го вы глубоко исследуете большие деревья без циклов, возвращающих нас назад к той же самой позиции, что практически противоположно задаче навигации робота. Поэтому мы разделяем разные методы, даже несмотря на то, что многие из них пересекаются в тех задачах, которые они охватывают.
Я надеюсь, что может быть однажды произойдёт объединение всех этих различных методов и тогда мы возьмём лучшие их части, лучшую терминологию и заставим всё это работать. Возможно один из вас, студентов, изобретёт способ как сделать это."
Чудеса логики достигли своего апогея, когда Норвиг
в очередной задаче заявил, что правильных ответов тут несколько и всё зависит от субъективной точки зрения... Например, игра в покер это, оказывается, не игра с элементом случайности - это, видите ли, игра в частично наблюдаемой среде! Ведь карты как-то там в колоде лежат, "просто" он не знает как... С такой точки зрения можно сказать, что стохастичных сред вообще не бывает и все среды частично наблюдаемые, ведь та же монета, например, падает одной из сторон потому, что она как-то определённо взаимодействует с пальцем, воздухом и Землёй, "просто" я не знаю как. Возможно это правильно, но тогда возникает вопрос: чему была посвящена добрая половина курса о принятии решений в условиях неопределённости?..
К превеликому счастью в обучающей части курса ни слова не было сказано про искусственные нейронные сети и генетические алгоритмы. Туда им и дорога.
Что касается организации самого курса то могу отметить следующее:
1. Недостаточная проработка задач. Слишком много вполне тривиальных неоднозначностей, которые преподавателям постоянно приходилось уточнять постфактум и сдвигать сроки выполнения заданий. Расписание занятий переписывалось по ходу дела, сервера периодически вываливались в "кофе-брейк", правильные ответы менялись после выставления оценок. Но несмотря на это всё, сам способ online-обучения доставил.
2. Перевод перестал появляться уже через пару занятий. Причём не только на русский, но и на все остальные языки. При этом на странице для набора переводчиков написано, что всё ok, дополнительные переводчики не требуются.
Вероятнее всего, преподы сообразили, что собрать урожай от своих усилий в виде новоиспечённых студентов Стэнфорда с хрустящими бумажками в карманах они смогу только с англоязычного населения, посему рационально решили, что расточать свою премудрость на весь мир - некошерно.

Коротко о преподах.

Питер Норвиг - учит пессимистично, занудно и неинтересно. Делает больше ошибок, чем Тран. Имеет тенденцию задавать неоднозначные вопросы с явной целью завалить ученика. Помешан на обработке естественного языка, чем снизыскал должность главного языческого гугловеда.

Себастьян Тран - явный маньяк своего дела, классический ИИчник. Утверждает, что увлёкся ИИ после гибели друга в автокатастрофе. Понимает психологию человека и, похоже, украдкой даже рефлексирует. Его лекции и стиль изложения материала поднимают настроение независимо от того, какую именно лабуду он рассказывает. Ввиду детской психической травмы одержим идеей безопасных самодвижущихся повозок, в чём изрядно преуспел и, для начала, выиграл 2005 DARPA Grand Challenge.
А
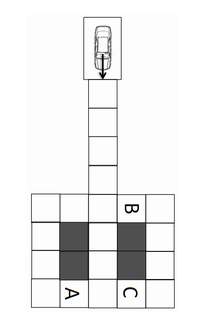
финальная задача финального экзамена какбэ намекает на главное достоинство профессора Трана:
Итог.
Если вы вступили в какие-то ИИ-курсы и вам с порога говорят, что задачи бывают разных типов - бегите оттудова как можно скорее! Там будут учить всему, чему угодно, только не ИИ.
Ведь ИИ - это
единый способ решения всех задач, по-определению.
Как только возникают "разные задачи", возникает дивергенция и далее вас будут учить только "разным" способам решения "разных" задач... Т.е. вместо конвергенции всех существующих методов в один метод - метод ИИ! - вас поставят на путь зла и бесконечного ветвления типов, видов, родов, классов, сортов и т.п. задач.
Как только вам сказали, что задачи бывают разных видов, это значит, что во главу метода поставлен живой человек со своим волшебным интеллектом, который чудесным образом умеет делить задачи на виды. Дальше вам навешают всякой лапши о тех инструментах-костылях, которые напридумывали люди за много столетий, лишь бы не заниматься ИИ, а продолжать самому решать "разные" задачи. Если вам интересно быть профессиональным вольнонаёмным рабом и решать задачи самому - вас ждёт увлекательный аттракцион. Если же вы хотите, чтобы задачи решал искусственный интеллект - забудьте о "разности разных задач" и думайте только о "единстве всех задач"! А когда все "разные" задачи станут задачами одного вида - одной задачей, тогда станет ясен и единый метод решения всех задач. Об этом -
в другом топике.