|
Обратное распространение ошибки - стандартный способ
обучения нейронной сети, хотя существуют и другие методы (о них в одной
из следующих глав). Принцип работы примерно такой:
1. Входной набор данных, на котором сеть должна быть обучена, подается на входной слой сети, и сеть
функционирует в нормальном режиме (т.е. вычисляет выходные данные). |
 |
2. Полученные данные сравниваются с известными выходными данными для рассматриваемого входного набора. Разница
между полученными и известными (опытными) данными - вектор ошибки. |
 |
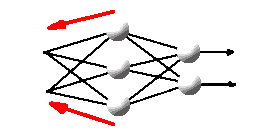
3. Вектор ошибки используется для модифицирования весовых коэффициентов выходного слоя с тем, чтобы при
повторной подаче того же набора входных данных вектор ошибки уменьшался. |
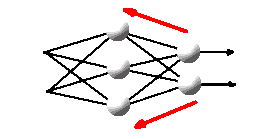 |
4. Затем таким же образом модифицируются весовые коэффициенты скрытого слоя, на этот раз
сравниваются выходные сигналы нейронов скрытого слоя и входные сигналы нейронов выходного слоя,
целью данного сравнения является формирование вектора ошибки для скрытого слоя. |
 |
5. Наконец, если в сети существует входной
слой (именно слой, а не ряд входных значений), то
проводятся аналогичные действия и с ним.
Следует заметить, что ошибка может
быть распространена на любой желаемый уровень
(т.е. в нейронной сети может быть неограниченное
количество скрытых слоев, для которых мы
рассчитываем вектор ошибки по одной и той же
схеме). Метод обратного распространения ошибки
напоминает мне волны прибоя, - входные сигналы
движутся в сторону выходного слоя (т.е. берега), а
ошибки - в обратном направлении (как и морская
волна вынуждена в конечном счете отступить от
суши).
Сеть обучается путем предъявления
каждого входного набора данных и последующего
распространения ошибки. Этот цикл повторяется
много раз. Например, если вы распознаете цифры от
0 до 9, то сначала обрабатывается символ "0",
символ "1" и так далее до "9", затем весь
цикл повторяется много раз. Не следует поступать
иначе, а именно, обучать сеть по отдельности
сначала символу "0" (n-ое количество раз),
потом "1", потом "2" и т.д., т.к. сеть
вырабатывает очень "четкие" весовые
коэффициенты для последнего входного набора (то
есть для "9"), "забывая" предыдущие.
Например, к тысячному повтору обучения символу
"1" теряются весовые коэффициенты для
распознавания символа "0". Повторяя весь
цикл для всего словарного набора входных данных,
мы предполагаем, что каждый символ оказывает
равноправное влияние на значения весовых
коэффициентов.
Запомните
Обозначим через переменную NUM_HID
количество нейронов в скрытом слое (нумерация
начинается с индекса 1). NUM_OUT - количество нейронов
в выходном слое.
Обратное распространение и формулы.
А теперь, настройтесь! Я собираюсь привести ниже
множество математических выкладок.
Во-первых, инициализируем пороговые значения и
весовые коэффициенты небольшими случайными
величинами (не более 0.4) Теперь прогоним сеть в режиме прямого
функционирования - процедура run_network (см. прошлую главу) Вычислим ошибки для выходного слоя. При этом мы
используем следующую формулу для каждого i-ого
значения выходного слоя (т.е. проходим по всем
узлам выходного слоя):
Ei = (ti - ai).ai.(1 - ai)
Здесь Ei - ошибка для i-ого узла выходного слоя, ai - активность данного узла,
ti - требуемая активность для него же (т.е. требуемое выходное значение).
Вот код на паскале:
procedure calculate_output_layer_errors;
var i : byte;
begin
for i:=1 to NUM_OUT do
with ol[i] do
E:=(desired_output[i] - a) * a * (1 - a)
end;
|
Здесь видно, почему я ввел переменную для ошибки непосредственно в описание нейрона. Благодаря
этому становится ненужным создание отдельного массива для значений ошибки.
Сейчас мы можем использовать значения ошибок
выходного слоя для определения ошибок в скрытом слое. Формула практически та же, но теперь не
определены желаемые выходные значения. - Мы вычисляем взвешенную сумму значений ошибок
выходного слоя:
Ei = ai . (1 - ai) . Sj Ej.wij
Смысл переменных по сравнению с прошлой формулой изменился незначительно. индекс i используется
для нейронов скрытого слоя ( а не выходного), Ei, следовательно, значение ошибки для нейрона
скрытого слоя, и ai - сигнал на выходе нейрона. Индекс j относится к нейронам выходного
слоя: wij - вес (весовой коэффициент) связи между i-ым скрытым нейроном и j-ым выходным нейроном,
а Ej - значение ошибки для выходного нейрона j. Суммирование проводится для всех весов связей
между отдельно взятым i-ым нейроном и всеми нейронами выходного слоя.
И вновь турбо паскаль. Обратите внимание, что сумма включает в себя взвешенные
связи только между рассматриваемым в данный момент нейроном скрытого слоя и всеми нейронами
выходного слоя.
procedure calculate_hidden_layer_errors;
var
i,j : byte;
sum : real;
begin
for i:=1 to NUM_HID do
with hl[i] do
begin
sum:=0;
for j:=1 to NUM_OUT do
sum:=sum + ol[j].E * ol[j].w[i]
E:=a * (1 - a) * sum
end;
end;
|
Полученные значения ошибок для выходного слоя мы используем для изменения весовых
коэффициентов между скрытым и выходным слоями.Мы должны вычислить все значения ошибок
до модификации весовых коэффициентов, так как в формуле присутствуют и старые значения весов.
Если же мы вычислим сначала весовые коэффициенты, а уже затем - значения ошибок, то
процесс обучения застопорится.
Применяем уравнение:
new wij = old wij + h.dj.xi
где wij - вес связи между нейроном i скрытого слоя и нейроном j выходного,
dj - приращение ошибки для выходного нейрона j и
xi - сигнал на выходе скрытого нейрона i, h - константа.
Эта константа используется для того, чтобы обучение не проводилось слишком быстро, то есть весовые
коэффициенты не изменялись слишком сильно за один шаг обучения (что является причиной прыжков
сходимости при обучении сети).
А как насчет пороговых уровней нейронов? Они также инициализируются небольшими случайными
числами и нуждаются в обучении. Пороговые уровни трактуются так же, как и весовые коэффициенты, за
исключением того, что входные значения для них всегда равны -1 (знак минуса - т.к. уровни
вычитаеются во время функционирования сети):
new threshold = old threshold + h.dj.(-1)
или ( в более удобном виде):
new threshold = old threshold - h.dj
Данная процедура обучает весовые коэффициенты и пороговые уровни:
procedure update_output_weights;
const
LEARNING_RATE = 0.025;
var
i,j : byte;
begin
for j := 1 to NUM_OUT do
with ol[j] do
begin
for i := 1 to NUM_HID do
w[i] := w[i] + LEARNING_RATE * E * hl[i].out;
threshold := threshold - LEARNING_RATE * E
end
end;
|
В этом коде я использовал j для индексирования узлов выходного слоя, чтобы привести в
соответствие с уравнением (т.е. E соответствует dj).
Таким же образом hl[i].out соответствует xi, а w[i] - wij.
Наконец, мы должны модифицировать веса скрытого слоя. В реальности, если имеются дополнительные
слои, приведенный код также работает.
procedure update_hidden_weights;
const
LEARNING_RATE = 0.025;
var
i,j : byte;
begin
for j := 1 to NUM_HID do
with hl[j] do
begin
for i := 1 to NUM_INP do
w[i] := w[i] + LEARNING_RATE * E * test_pat[i];
threshold := threshold - LEARNING_RATE * E
end
end;
|
Все то же самое на JAVA
Ниже приведена реализация нейронной сети, обучаемой методом обратного распространения ошибки на JAVA:
Если вам нужен исходный текст, то кликните здесь. Конечно же, изменяйте его
как хотите.
Если вам нуже скомпилированный код, который вы конечно же можете включить в свою веб-страницу,
то кликните здесь.
Сеть, как она здесь представлена, имеет фиксированное количество входов (6) и
фиксированное количество выходов (5). Скрытые узлы в середине изображены синими кружками.
 |
Обучающие наборы представлены по левую сторону. Для того, чтобы изменить входные
наборы, желаемые выходные наборы, кликните на столбец из шести входных квадратов или на
столбец из пяти выходных квадратов. Каждый клик мышью затемняет квадрат (белый - 0, светлосерый -
0.3, темносерый - 0.7, черный - 1). |
 |
Эта комбинация, например, обозначает, что для входного набора установлены данные
(1, 0, 0, 0.3, 0, 0.7), а для выходного набора - (0, 0, 0.7, 0.7, 0). Кликните на символ + или - (около
словосочетания "Training patterns") для изменения количества наборов. |
Для того, чтобы обучить сеть, кликните на кнопку "Train". Для тестирования
сети введите значение компонента входного набора в слот наверху, а затем кликните на
компонент входного набора (на одно из тех текстовых значений в рамке слева на структурной
схеме сети). Запустите сеть - кнопка "Run"
|

 материалы
материалы