Автор: гость
Современные CPU отстают от GPU в тысячи раз
|
|
Это от криворукости программистов.
На других форумах пару раз постил картинку 2015г о правильном допиливании некоторой нейросетевой библиотеки под CPU.
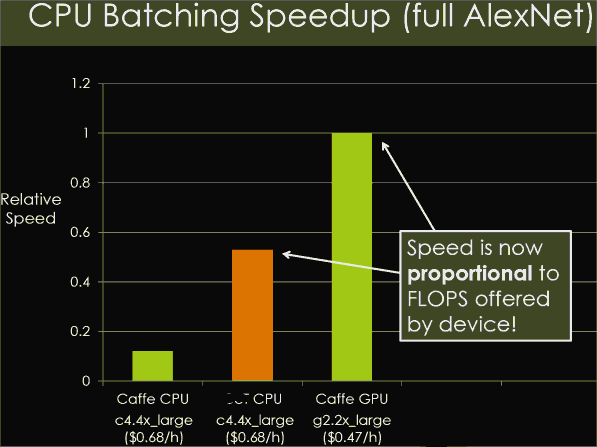
Посередине - результаты допиленного варианта либы, работающего на процессоре. Бывшая разница в порядок между базовым CPUшным вариантом (слева) и вариантом для GPU (справа) - справедлива только для конкретного кода, а не для случая "в общем" (ибо видим, что другой код опроверг эту разницу в порядок)
В общем, всё определяется только теоретическими Гига/ТераФЛОПСами устройства. А не его внутренней степенью параллельности.
Там, кстати, последней строкой на картинке - почасовые цены аренды амазоновских серваков, на которых это тогда запускалось. ЕМНИП, сейчас картина поменялась - серваки с видяхами стоят дороже, т.е. более медленное решение может быть экономически выгоднее.
Есть и другой случай - поиск объектов на видео. Пока размер кадра позволяет держать и данные, и модель в CPUшном кэше - паритет с видюхой. Но с какого-то размера - нескольких мегабайт кэша процессора перестаёт хватать, а у видюхи ОСТАЮТСЯ ГИГАБАЙТЫ её быстрой памяти. Если кого интересует - тоже картинку с результатами найду.
Т.е. не путайте скорость самих вычислителей - и зависимость времени вычислений от объёма быстрой памяти (или от скорости доступа к памяти).
Ну и как-то ссылался тут на буржуинскую ВУЗовскую лекцию 2008г о вариантах написания функции перемножения матриц на CPU. В зависимости от
криворукости программиста выбранного программистом решения/языка (и в зависимости от знаний программистом архитектуры процессора и системы его команд) - разница может доходить до почти 300000 раз. Я не ошибся с числом нулей - почти 300000 раз. Триста тысяч, да.
Тут тоже интересующиеся могут спросить ссылочку.