Автор: Capt.Drew
Был у нас кыевлянин Александр Тумак (на Мембране) |
|
Тумик и на Образце бывал. Интересный собеседник, но сильно занятой.
Автор: Павел Фоменко
этот способ исходит из АНАЛИЗА пикселов |
|
Синтезировать совсем без анализа никак нельзя. Любой рецептор состоит из дискретных элементов, из которых мозг синтезирует некий пространственно детерминированный образ. Не говоря уже о знаниях. Прежде чем синтезировать новое знание нужно иметь набор дифференцированных знаний.
Автор: Павел Фоменко
пикселам изображения вы пытаетесь назначить некие взаимоотношения (почему-то связывая их закономерностью 1/R^2) |
|
Взаимодействие очень простое. В линейной зависимости от расстояния точки пересылают друг другу "кванты движения".
Автор: Павел Фоменко
в расспознавании есть смысл перейти к другим взаимоотношениям и, соответственно, к другим пространствам
символ - это процесс создания символа
из способа "линия" мы можем перейти к способу "угол" или "дуга" |
|
Уверен, что это самый правильный путь! Символ должен представляться в виде последовательности действий, необходимых и достаточных для его создания. Я планирую выявлять эту последовательность через выяснение связей, которые удерживают символ в целостности при внешних возмущающих воздействиях.
В сущности, восприятие - это тот же эффектор и не будь он способен координироваться с другими эффекторами он был бы не нужен.
Вспомнилось как дети рисуют букву "Е". В самом начале все дети рисуют много горизонтальных палочек, видимо потому что в "подпрограмме" (ритуале) для рисования этой бквы у них появляется действие - "рисуй палочки", но ещё не появляется действия - "прекращай рисовать палочки". В активации и торможении действий собственно и заключается вся координация, всё наше знание.
Автор: Slava
конфигурация это - не только структура |
|
Структура - это следствие конфигурации. А конфигурация - это адресность взаимодействий и кванты взаимодействий. В этом смысле очень понравилась книжка
Клименко А.В. "Рекуррентная теория самоорганизации".
Автор: Slava
подмена термина ничего в данном случае не дает |
|
Если подмена термина позволяет понять, что восприятие - это эффектор - то даёт.
Автор: Slava
К сожалению, все - то же, но теперь с твердым знаком
Ладно, не мучайтесь |
|
Да уж, хорош подарочек.. Но
дело принципа! Там действительно была ошибка, даже не знаю как оно у меня работало. Если в этот раз не получится - спишем на мистику

Автор: Slava
Подозреваю, что чрезмерное упрощение задачи может вас сильно увести в сторону от желаемого |
|
Я рассматриваю этот распознаватель просто как подготовку к чему-то более серьёзному и адекватному.
Собственно мой первый
распознаватель рукописных печатных символов! За качество распознавания прошу сильно не бить, это всего-лишь игрушка.
Как работает программа.
При запуске открывается окно с белым квадратом - на нём можно рисовать. Можно загрузить символ из файла (кнопка "Open picture"). Кнопка "Reload" перезагружает файл или стирает картинку если файл изначально не был загружен.
После нажатия на кнопку "Do it" выполняется следующий алгоритм.
1. "Включается" взаимодействие между всеми точками буквы по типу притяжения.
2. Программа отслеживает момент скелетизации буквы и останавливает притяжение.
Типичная картина изменения плотности изображения буквы при притяжении выглядит так:
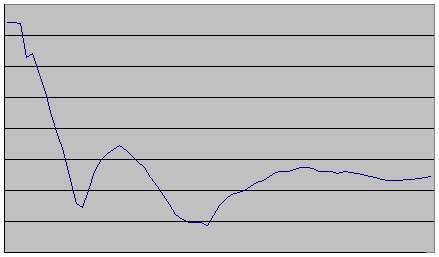
Первый существенный минимум - это скелетизация. Второй минимум - это сжатие в точку. Неудивительно, что буква сжимается в точку за два этапа. Интенсивность взаимодействия между более близкими точками больше, чем между более дальними. Поэтому процессы локального сжатия опережают процессы глобального сжатия.
Программа ищет минимум в диапазоне 6 последовательных замеров плотности. Справа в окошке можно видеть как меняется плоность буквы (первое число) и разность между текущей и предыдущей плотностью (второе число).
Конечно, есть более быстрые алгоритмы скелетизации, но здесь важно соблюсти чистоту идеологии - всё должно быть построено на едином принципе - взаимодействие, связь, движение.
3. Максимально скелетизированная буква отрисовывается и все её точки подвергаются взаимодействию типа "отталкивание".
4. Отталкиванию препятствует окружность, которая проведена из центра масс буквы до самого дальнего пиксела буквы. Можно видеть как точки "оседают" на этой окружности.
5. После того как остановится последняя точка, программа делит окружность на 100 секторов и подсчитывает число точек попавших в каждый сектор.
6. После этого программа последовательно сравнивает данное распределение плотности по окружности с 33 эталонами, поворачивая его вокруг центра масс с шагом 3,6°. Для каждого эталона запоминается минимальное отличие и угол, при котором оно было обнаружено.
Эталоны были созданы по такому же принципу - просто однократным применением алгоритма к символам, которые лично я посчитал идеальными

7. В окошке справа выводятся отсортированные сверху-вниз результаты распознавания. После буквы следует мера похожести (чем число меньше, тем больше буквы похожи) и угол на котором был получен минимум отличия.
Выводы.
1. Качество распознавания слабенькое из-за того, что скелетированная буква при разлёте испытывает накапливающееся влияние неоднородностей, что вызывает "эффект бабочки".
2. Использование эталонов - это не совсем честный приём. Желательно, чтобы программа сама строила классы изображений. Но для этого, имхо, нужно чтобы она делала это в процессе обучения, а не пытаясь разделить на классы полученное множество признаков. В идеале я вижу это так:
- есть некий базовый класс
- есть мера допустимого различия между классами
- есть первый образ. Первый образ всегда относится к первому классу.
- другие классы для поступающих образов создаются при превышении допустимого различия между ними и первым классом. Такой мерой может быть что-то вроде устойчивости класса.
3. Данный тип распознавания - это своего рода сравнение значений хэш-функций. Многие изображения могут давать одинаковую плотность распределения на окружности, но для некоторых букв оно даёт достаточную меру различия. Если посмотреть как сортируются буквы при распознавании, видно что они сортируются, в общем-то, по похожести между собой.
4. Замечено, что если буква распознана неправильно, то угол, определённый для верной буквы, обычно соответствует нарисованному. Это можно использовать для улучшения качества, если допустить, что правильно ориентированные буквы более вероятны.